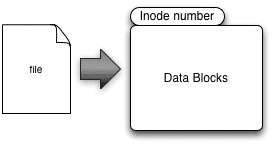
Inodes
Every file in a Linux/Unix operating system has an inode associated with it with an exception of Solaris ZFS, which does not have inodes. Inodes basically work very similar to an appendix of a book. Every Inode will have below information about the file.
1. owner
2. permissions
3. size
4. time of last access
5. creation time
6. group id
7. Pointers to data blocks associated with the file content
Note: Inode does not provide filename however.
2. permissions
3. size
4. time of last access
5. creation time
6. group id
7. Pointers to data blocks associated with the file content
Note: Inode does not provide filename however.
File Types
There are basically 5 types of files in any unix operating system.
1. Regular
2. Directory
3. Symbolic links (hard link & soft link)
4. Device files (character special and block special device)
5. Named pipes
The Character in the first column of ls -l command identifies the type of a file.2. Directory
3. Symbolic links (hard link & soft link)
4. Device files (character special and block special device)
5. Named pipes
# cd / # ls -l bin lrwxrwxrwx 1 root root 9 Sep 19 15:41 bin -> ./usr/bin
- Regular files d Directories l Symbolic links b Block-special device files c Character-special device files p Named pipes
Files and Directories
The regular files can store different types of data and can be easily created using touch command or vi editor. Directories hold the association between files and/or directories and inode numbers.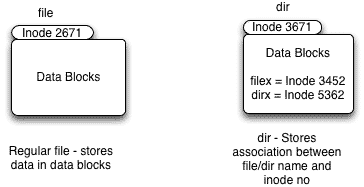
Soft links
As shown in the diagram soft links or symbolic links simply points to another file. It only contains the pathname of the file to which it is pointing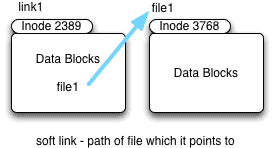
# touch file1 # ln -s file1 link1 # ls -l -rw-r--r-- 1 root root 0 Sep 19 14:41 link1 lrwxrwxrwx 1 root root 5 Sep 19 15:41 link1 -> file1
3. If you delete the original file (file1) the soft link render as useless.
4. Soft links can reside on different file systems.
Hard links
Every file uses atleast one hard link. So when you create a new file a new directory entry is created which is called link count. So when you create a new hard link to this file the link count increaments by 1.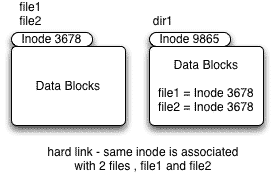
# touch file1 # ls -l -rw-r--r-- 1 root root 0 Sep 23 13:19 file1 # ln file1 file2 # ls -l -rw-r--r-- 2 root root 0 Sep 23 13:19 file1 -rw-r--r-- 2 root root 0 Sep 23 13:19 file2 # ls -li 1282 -rw-r--r-- 2 root 0 root 0 Sep 23 13:19 file1 1282 -rw-r--r-- 2 root 0 root 0 Sep 23 13:19 file2 # find . -inum 1282 ./file1 ./file2
3. Even if you delete any one of the file, it has no effect on the other file. Only the link count decrements
4. Hard links can not cross the file system.
Device files
In UNIX operating system any physical device has a file associated with it called as device file. It’s an interface that interacts with device drivers. Unlike other file types they do not hold any data in data blocks instead they use the inodes to store the major and minor no for any device file.
# cd /dev/ # ls -l crw-r----- 1 root tty 4, 0 Sep 23 12:51 tty0 brw-rw----- 1 root disk 8, 1 Sep 23 12:51 sda0
minor device no – specific unit of the type that the device driver controls.
For example if you have 10 HP printers, the major no will be the HP printer devices driver and minor no would be the instance of printer (1,2 .. upto 10).
Device files are of 2 types
1. Character special
2. Block special
Character special Device files
1. Character “c” in the filrst column of ls -l command output identifies a character special device file
2. Data is accessed as data stream (character by character , 1 byte at a time)
3. Example : tty, serial, virtual terminals
# ls -l crw-r----- 1 root tty 4, 0 Sep 23 12:51 tty0
1. Character “b” in the first column of ls -l command output identifies a character special device file
2. Data is accessed as defined block size for that device
3. Example : Hard Disk, CD/DVD
# ls -l brw-rw----- 1 root disk 8, 1 Sep 23 12:51 sda0
Named Pipes
- Named pipes are special files which are used for interprocessor communications. Unlike normal pipes you can read from and write to the named pipes. For this reason they are also called as FIFO (file in file out).- mknod() or mkfifio() are common examples which make use of named pipes in order to access the pipe by name.
- As shown in the example below 2 processes (gzip and cat) can simultaneously access the Named pipe to write to and read data from it.
# mkfifo test_pipe # gzip -9 -c > test_pipe < out.gz # cat file1 > test_pipe # ls -l test_pipe prw-rw----- 1 root root 0 Sep 23 12:51 test_pipe



